

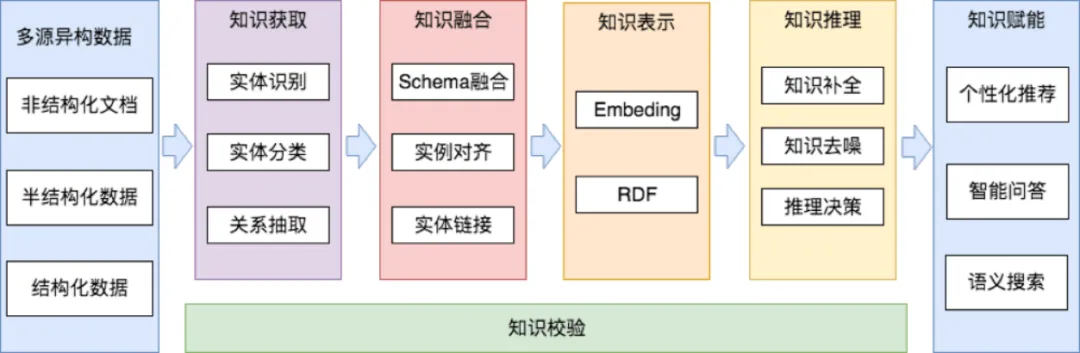
作为人工智能的重要研究领域之一,知识图谱的研究和发展已经走完了它的前半程。2012 年,谷歌 Knowledge Graph 产品初步成形,开启了知识图谱时代。到现在,知识图谱已经被广泛应用在自然语言处理的各项任务中,如金融、电商、医疗、政务等众多领域的信息搜索、自动问答、决策分析等。构建知识图谱需要四个步骤:数据抽取、数据融合、数据推理和数据决策。
所以,知识图谱是源于数据的。数据是一,算法是零。数据决定了知识图谱技术应用的上限,而算法则可以帮助我们无限逼近这一上限。数据的好坏,将直接关系到知识图谱构建的效率和质量。而这些数据,现在通常通过多个渠道来获取。比如通过爬虫的形式获取网络中的开放数据,比如媒体网站和国家政府网站等等。也有通过机构合作或购买版权的形式获取的数据,如 Digital Science、中国工程院等。这些不同来源的数据,会通过算法进行融合与关联,为知识图谱构建提供基础。于是问题出现了。算法真的已经成熟到了可以完全理解数据中的逻辑,某个行业领域内的知识或常识整理成结构化的形式,然后在此基础上进行推理和决策了吗?很遗憾,正如每个人的经验认知有“壁”,自动化采集而来的信息来源驳杂,甚至无法保证正确性,目前的算法也仍未学会复杂的人类常识与处于不断变化中的信息的衍生义,更遑论在这样的数据基础上来构建知识图谱,进行决策。既然自动化采集信息构建知识图谱缺陷明显,那么使用人工来尝试进行知识图谱的构建呢?人工构建可以享受各个领域专家多年的知识沉淀红利,又避免了算法作出的决策有悖于人类的道德或情感。甚至还可以进行信息溯源,确保数据的质量。

(《生化危机》Red Queen )优势这么多,却依然没有被大范围采用的知识图谱的人工构建,这中间发生了什么?因为人工构建的速度相对慢,经常跟不上信息的演进思路,而且(人工)成本更高。如果能将人工与自动化相结合,知识图谱的的构建质量与效率是否会稳步提升?已经有人想到并且这么做了。如果以计件激励的形式,在高考前,就能收集大量高校内的老师教授、在校/毕业学生以及社会人士对高校的评价,再经过教育领域专家及报考指导老师的识别与筛选,通过算法将信息整合打包,输送给报考咨询机构、高校招生机构和教育部门形成知识图谱,就可以给全国范围内的考生生成可信赖的报考建议,避免了信息差异造成的人才损失。这就是铭识协议(Epik Protocol)想做的事情。这是一个依托区块链技术知识图谱协作平台。它通过激励措施,组织全球范围内的用户共同协作,将各领域知识梳理成为知识图谱,分布式地永久保存,为现有的人工智能语言模型提供源源不断的高质量数据,来推动知识图谱在生产生活领域的应用。在铭识协议的体系中有三个主要角色,赏金猎人可以自由领取各个知识领域的任务,完成提交验收;领域专家负责专业任务的拆解和验收,且将数据上传至知识矿工;知识矿工可以行驶治理权力,参与领域专家选拔投票以维护生态良性发展。从数据的生产到验收到核心专家的选拔,形成了一套行之有效的生产管理闭环。
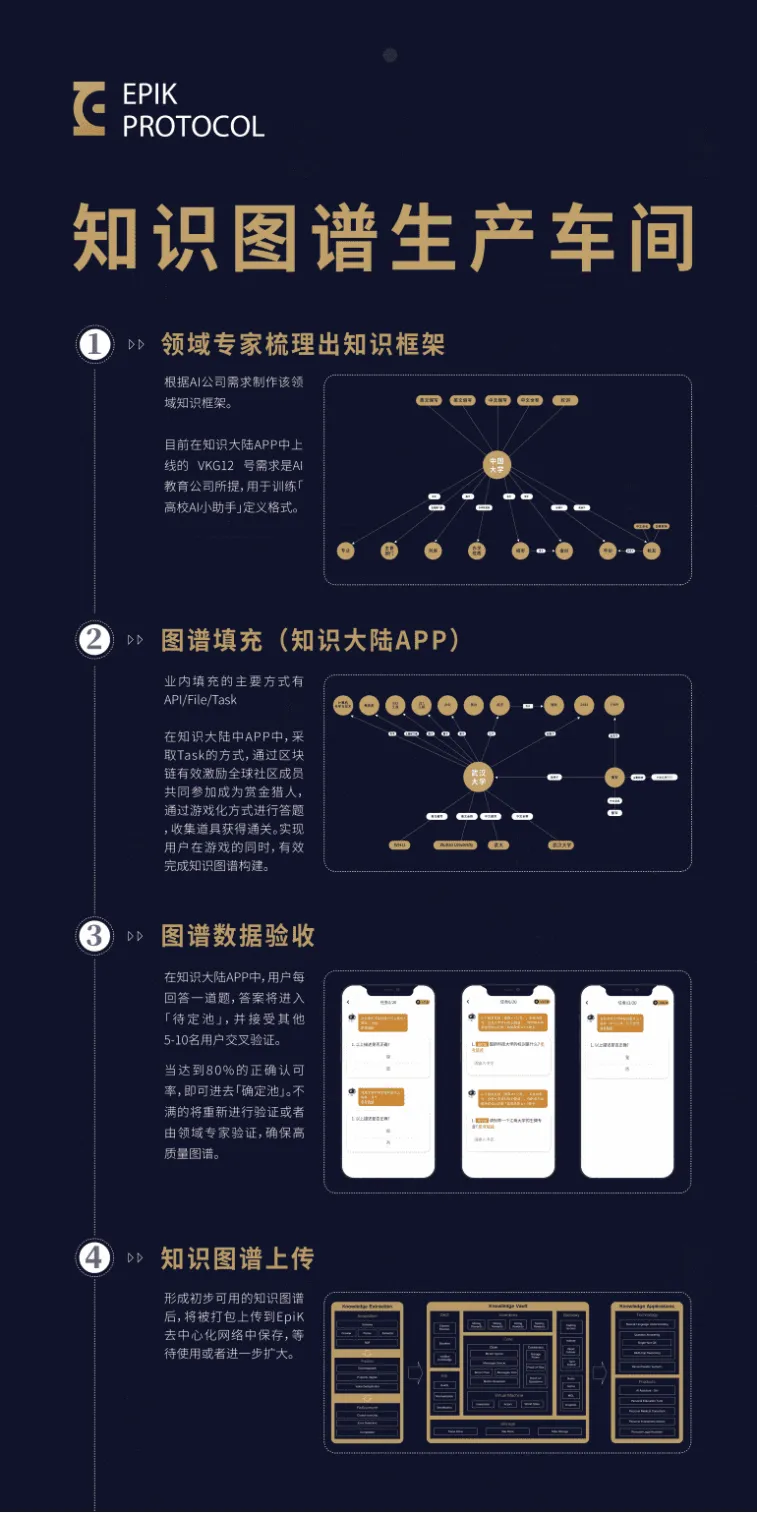
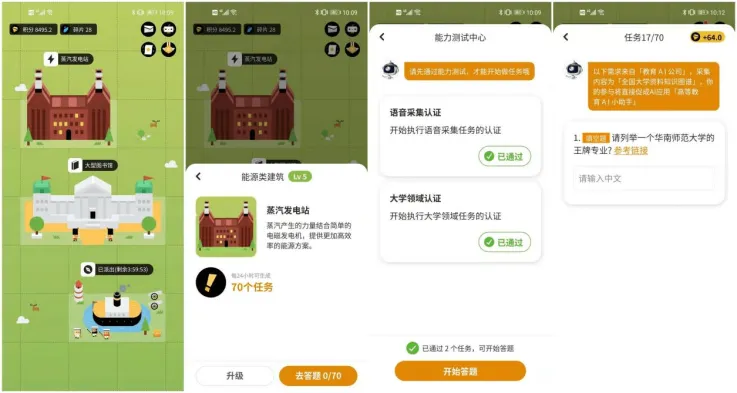
他们还创新地将枯燥的数据筛选过程以游戏的形式体现,参与数据的识别与筛选,赏金猎人们就可以获得相应的奖励。而且不用担心难度太过艰深,因为早有专家做好了难度拆分。在游戏的过程中完成对数据的人工处理,一边升级一遍赚取奖励,铭识协议以这种形式吸引更多的赏金猎人参与其中,来弥补知识图谱人工构建的效率和质量弱势。
已经筛选和加工好的数据去了哪里呢?区块链技术发挥了它的优势。为了满足特定领域的有序存储需求,铭识协议对数据质量有明确要求,存储完全免费。他们在各个领域收集有序的知识图谱小份日志文件,再定期将各个领域小份日志文件合成大份快照文件后上传到分布式存储的⾃由开放市场 Filecoin 上做快照备份,发挥 Filecoin 大文件冷存储的优势的同时,也持续提供了有效数据。知识矿工作为上传数据的中间人,是铭识协议体系内至关重要的一环,当然也不会空手而归。带宽补贴与知识基金储备,都将是他们的劳动所得。人工+自动化,这种半自动化的知识图谱构建方法在将来一段时间内仍然会是主流,尤其对医疗、安全和金融等领域,数据质量要求较高,需要通过人工审核保证准确性。知识图谱的构建研究已经走到下半场。把知识图谱协作闭环的工具做好,让协作更简单,这将成为这一赛道上绕不过的一环,也是各个企业机构竞逐角力的一环。谁会在这个领域脱颖而出,谁就有机会与能力,率先得到进入到 Web 3.0 时代的船票。