

地球上的生物多种多样,天空,海洋,大陆,甚至是地底深处,都有生命存在。个体生命活动的进行、种群的繁衍、生物种间的关系调节、生态系统的稳定性维持,归根结底都是信息的传递。
将这些驳杂的信息提炼成文明并将其线上化,加速碳基生命向硅基生命的进化,正是我们想要做的。
分布式存储的时代还没有到来
互联网的发展给人类带来便利,也带来了如洪流爆发般的数据体量。
受限于互联网底层协议 HTTP 的中心化特点,一旦服务器出现故障,网络传输就会受阻,从而出现宕机。人们想要解决这种根本的结构性问题,于是分布式存储应运而生。
分布式存储的概念太热了。市场上涌现了一大批分布式存储项目,Filecoin、Sia、Arweave、Subspace Labs……它们都在争先恐后证明自身技术的领先性,试图抢占更多的市场份额。
存储市场发展的前提,首先要有大量需要被存储的数据,而这就要求产生数据的应用达到一定的规模量级。
而目前的中心化的公司并没有大规模使用分布式存储,原因很简单,他们不需要。中心化公司的产品大多是中心化应用,他们的业务逻辑都是在中心化服务器上运行,中心化存储更便于他们管理数据。并且,分布式存储的成本对中心化公司来说,也更高。如果一定要选择,各大互联网平台的云服务,价格可谈的空间更大。
没有需求,概念炒得再火热,最终也会被淘汰,因为科技圈里最不缺的就是新概念。而盲目创新、崇拜技术,但与真正的用户需求不匹配,那么再领先的技术也无法真正实现落地应用。
所以我们认为,分布式存储爆发的时代,其实仍未到来。但这种领先的理念与技术,仍然具备超前的价值,为我们提供了灵感。
AI数据售卖,一个被验证了的商业模式
商业不是游戏。没有严谨地调查与论证,贸然踏入一个领域,是对团队和合作伙伴、投资人、投资机构的不负责任。
但 AI 数据集的售卖,是一个被验证了的商业模式。
数据集的需求太大了。
IBM 的 5 亿行代码(bug)数据集、清华大学与阿里巴巴 460 万样本 NER 数据集、面部微表情识别数据集、问诊方案数据库……相比遭遇瓶颈的算法,数据现在成了 AI 行业的抢手资源。
精准优质的数据可以使 AI 在细分领域取得更好的模型效果,甚至可以说,很大程度上,是数据质量在决定 AI 模型的性能。
根据德勤出具的研究报告,2021年,AI 市场将会有近 3 万亿美元的市场需求,且每年以30%的速度在增长。而这其中,AI 数据的市场缺口至少达 70 亿美元(数据来源:美国大观数据研究公司)。
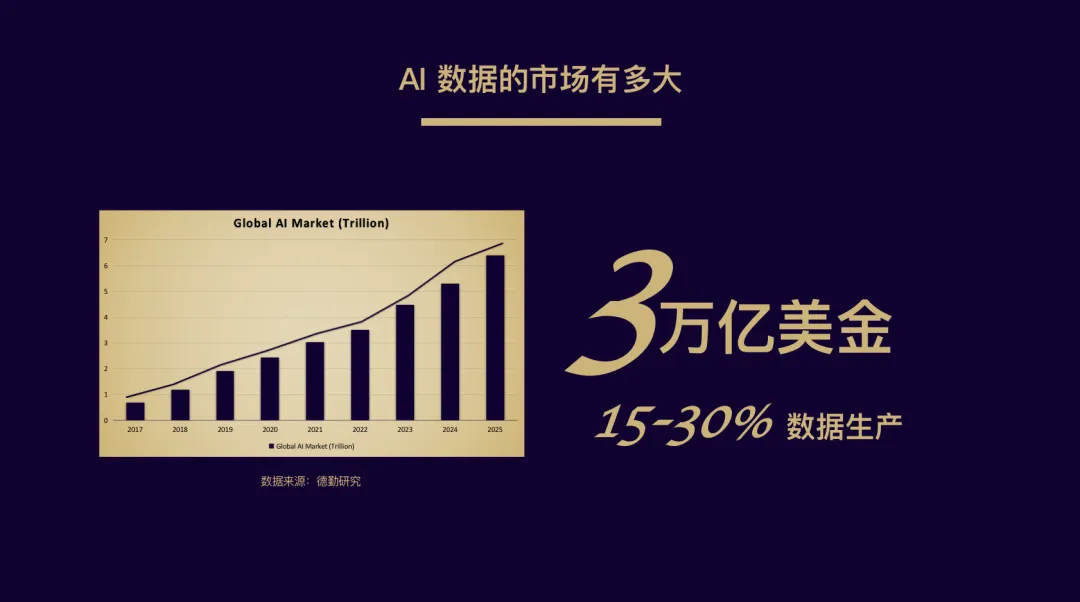
在这样的市场规模下,AI 公司仍然对两个困境束手无策:数据质量与成本控制。
对 AI 的训练数据来源于无数人类根据自身学识与经验的标注。而伴随着 AI 模型对数据品质要求越来越高,数据标注需求变得越来越垂直、越来越精细,对标准人员的素质和专业知识要求也越来越高。相对应的,人员的成本越来越高,数据价格也随之水涨船高。
这一次为我们提供灵感的,是热度刚刚过去没多久的共享经济。数据与存储,是后摩尔时代里两个绕不过的议题。
如果说分布式存储概念的出现为人类解决了“存在哪儿”“怎么存”的问题,那么“存什么”的拷问再一次摆在人们面前。如何甄别无效数据、系统化地整理零散数据?如何将图片、视频、音频等呈指数增长的海量非结构化数据要发挥其价值?
铭识协议 EpiK Protocol 以采用 AI 数据的分布式存储协议,来赢得这场存储资源的抢夺战。
AI 人工智能数据已经在逻辑分析和数据洞察、市场预测层面证明了自身的 B 端商业价值。分布式存储的商业模式也将被改变,售卖存储已经成为过去式,将被标注好的 AI 数据进行分布式存储,以打包数据的形式提供给数据企业,有利于更高效地利用资源。
将有价值的数据放在有限的存储空间里,漫长且繁琐,但这是文明链上化的必经之路。
在存储与数据的迷宫里找出路
以众包形式进行 AI 训练数据的标注工作,以共享经济的分红形式给予数据标注人员以收益,降低成本的同时保证数据质量。
而这种写入多读取少的高价值的 AI 数据,对存储的可共享存在一定的需求。于是,分布式存储终于找到了它渴望的有效数据。
将 AI 数据与分布式存储结合,为 AI 训练提供优质的标注数据,是我们为铭识协议 EpiK Protocol 规划的商业模式。
万事俱备,但还有一座必须要征服的“高山”——铭识协议 EpiK Protocol 将如何解决 AI 标注数据质量参差不齐的问题?
随着大模型,如 BERT、Alphafold2、GPT-3、DALL·E 逐渐成为人工智能产业的潮流,更多的数据也在被“投喂”进各种 AI 模型中。AI 并没有分辨数据的能力,数据的质量越差,AI 输出虚假或者错误信息片段的可能性就越高。
语音识别、面部识别、问诊机器人、代码bug这类细分领域数据集,对 AI 数据标注者的个人素质与专业知识的需求也不尽相同。
EpiK为此特别规划了一个“AI 数据标注系统”。
在这个系统中,有三个重要的角色。领域专家必须是由来自各行业的有一定工作年限和专业资质的资深人士担任,他们负责设计所在领域的 AI 数据格式,根据 AI 训练的需求制定统一的标准,规范标注数据的提交,同时还肩负了数据质量验收、上传的重担;数据标注师则来自世界范围内的各行各业,他们将以自身的专业知识和经验来进行数据标注,同时根据领域专家对已提交数据的评级,按照评级获取酬劳;知识矿工则需要将领域专家上传的数据打包至分布式存储,以供 AI 训练企业/机构下载,当然只是矿工也有治理权力,可以参与到领域专家选拔投票中,以维护整个“AI 数据标注系统”的良性发展。
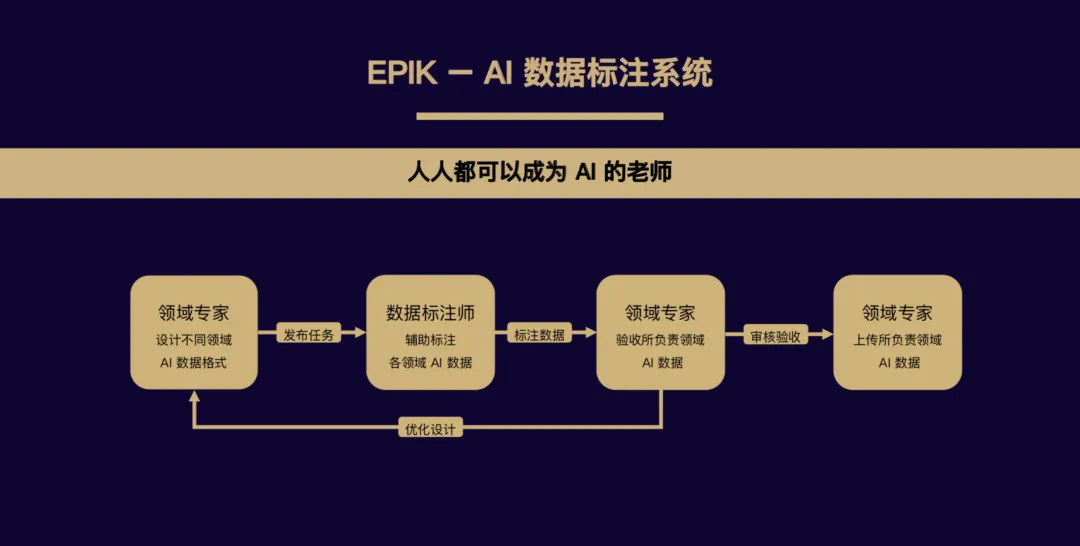
而且,为了增加标注师工作的趣味性,铭识协议 EpiK Protocol 将这部分工作在终端以游戏通关的形式呈现(App:知识大陆),降低了参与门槛,让人人都可以成为 AI 的老师,同时也提升了标注师们的体验。

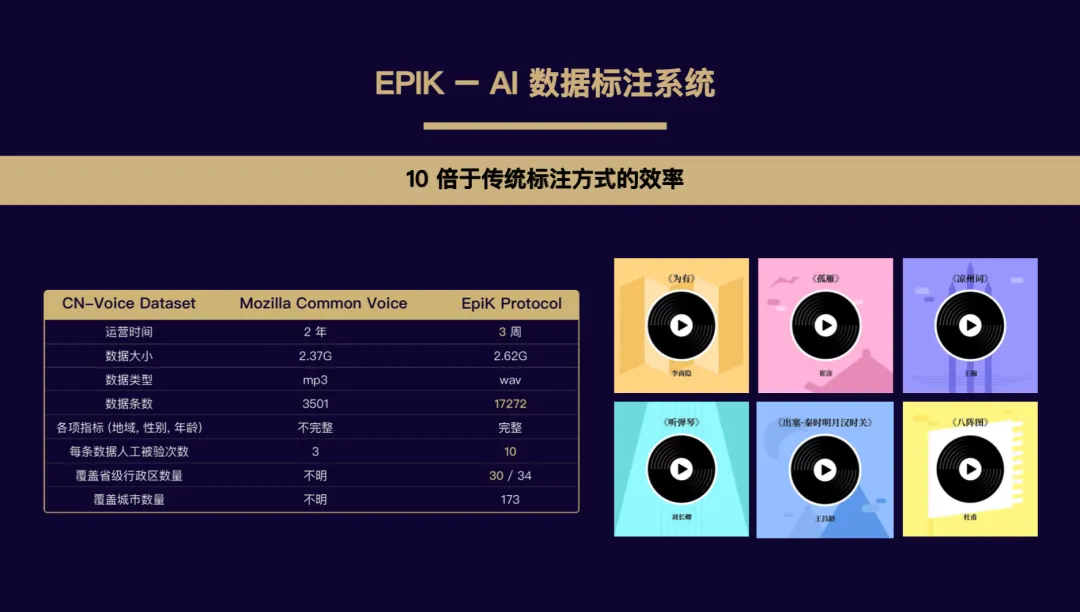
经过测试,以“知识大陆”形式收集 AI 标注数据的效率为传统标注收集方式的 10 倍左右。开发开源 Firefox 浏览器的非营利组织 Mozilla 开源语音收集计划 Common Voice,用 2 年的时间,搜集到了 3501 条中文语音标注数据,占用存储 2.37 G,每条数据的人工校验次数平均为 3 次,数据来源的低于、性别和年龄指标不完整,覆盖地区不明、覆盖城市数量不明。而经过“知识大陆”试运行 3 周的数据来看,收集中文语音标注数据 17,272 条,且每条数据标注者所在地域、性别和年龄皆可溯源,全部占用存储 2.62 G,平均每条数据的人工校验次数为 10 次,数据来源覆盖国内 34 个省份,173 个城市。
与“AI 数据标注系统”相对应的,是铭识协议 EpiK Protocol 规划的“AI 数据存储系统”。
为了充分调动其每台闲置中的存储设备,在“AI 数据存储系统”中存储数据是免费的,且不限时间,默认无限存储份数,无需指定特定节点。平均每个扇区大小仅需 8M,相比于 FileCoin 32G的平均扇区大小,“AI 数据存储系统”的更节省空间,对存储设备的要求门槛更低,参与更容易。
不过,为了保证标注数据的存储质量,只有上传经过领域专家验证过的数据,才会计入算力。再一次通过规则来规避“脏数据”混入高质量的数据中。
目前,铭识协议 EpiK Protocol 的商业模式和理念已经得到了世界级人工智能专家——人工通用智能之父 Ben Goertzel 的认可,并且我们成功地说服他加入,成为了铭识协议的首席顾问。
目前全球最大的 NGO 开源开放数据组织 Open Knowledge,全球最大的中文知识图谱库 OpenKG.CN,全球最大去中心化的数据交换协议 Ocean Protocol,全球最大的开放中文语音数据社区 OpenSLR,全球首个去中心化 AI 服务网络、全球首个机器人公民 Sofina 缔造者 SingularityNET,全球高质量 AI 数据提供者 iMerit 以及清华大学,都是铭识协议 EpiK Protocol 的公开合作伙伴。

目前,主网将于今年 8 月15日正式上线。作为全球首个 AI 数据的分布式存储协议,我们要做的,是将人类积累了上千年的文明的信息上链,为 AI 叩响智慧的大门,“这将是一场至少延续 50 年的碳基生命向硅基生命的史诗级布道”。