

你比自己意识到的还要聪明得多。
如果有人问,皇后乐队(Queen)和林肯公园(Linkin Park)的成员数一样多吗?若对这两个乐队并不陌生,你可能会第一时间反问“怎么可能?当然不一样”。


但其实,你的大脑为此很是经过了一番推理和运算:它首先需要高速运转,翻找出两个乐队的相关记忆,明确每个乐队有哪些成员,然后分别对两个乐队的成员进行计数,最后对计数结果进行比较。
这种经过多跳的推理,还需要进行计数、比较,甚至是逻辑运算的操作,就是我们的大脑在处理复杂问题得出答案的过程。
你可能会惊讶:这不过是一个非常简单的常识问题而已!不过,对于人工智能(Artificial Intelligence)来说,这已经是很复杂的问题了。
对人工智能的研究,让人类重新理解了自身的思维过程。
—
1923 年,Ogden 和 Richard 提出了经典的“语义三角”模型。在这个模型里,人们将客观世界事物的认识概括抽象为概念(Concept),建立起概念和事物、概念和概念之间的关系,将客观世界中的实体与脑海中的概念对应起来,从而通过概念来认识和理解世界,形成自身的知识系统。
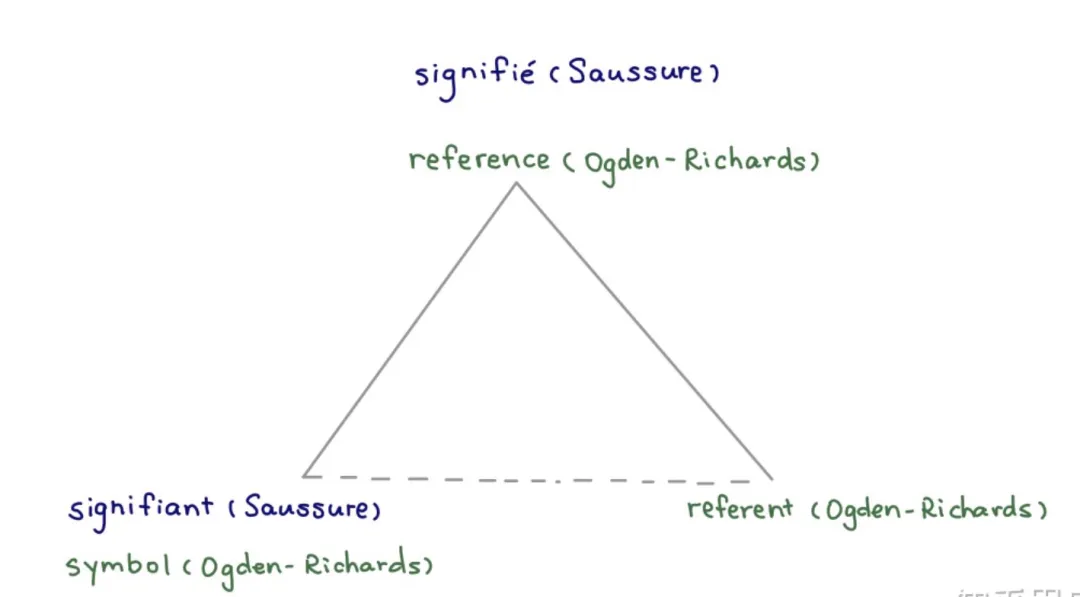
认知是人类获取并应用知识的过程,知识图谱是人表示客观世界认知的一种形式。
知识图谱的意义非凡。谷歌使用知识图谱表示语义网络,在搜索领域中发展得如鱼得水。有时你会觉得某宝某东某音某书比自己还了解自己,就是因为研究人员已经构建起了各种通用或专用知识图谱,这些知识图谱在语义搜索、推荐系统,问答系统等应用场景下发挥了很大的作用。
但并不是有了知识图谱的人工智能就能与人脑媲美。即使使用了维基百科等知识图谱的结构化知识,当面对人类提问的时候,匹配上答案只有约 2%。
面对着沉淀千年的浩如烟海的文明,进化百万年的人脑举一反三,而年轻的人工智能还在举三反一。仅靠学习成熟的概念无法教育出一个成熟的符合人类三观的人工智能,否则就不会出现在手滑点赞过一个吃播博主后所有的推荐都是吃播、好奇购买过一个儿童玩具后购物软件就默认你已经有了一个孩子这样的属于这个世纪的特有的笑话。

只是,代码不会说谎,喂给它什么样的数据,它就会产出什么样的结果。所以,高质量的合乎逻辑的数据,将成为人工智能最优质的食物,它也会回报你想要的结果。因此,在人工智能进化的过程中,一个不受中心化控制、能激励各方力量参与共建、数据安全可信防篡改的知识图谱数据库必不可少。
区块链技术的意义凸显了出来。
铭识协议 EpiK Protocol 借助区块链技术,创造了一个去中心化的共建共享共益的安全可信知识图谱协作平台,通过可信存储、可信激励、可信治理和可信金融四大核心能力,以极低的管理成本组织全球社区用户共同协作,将人类各领域知识转化为AI可以理解的知识图谱数据,开阔AI的认知,推动认知智能时代的到来。
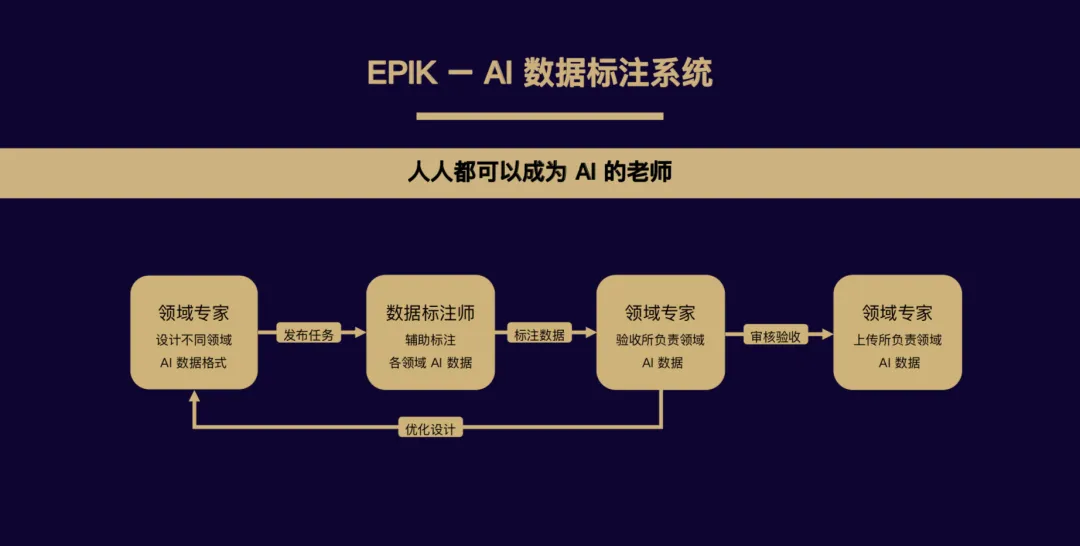
为了能更好的把控喂给人工智能的数据质量,铭识协议规划了一个独创的“AI 数据标注系统”。在这个系统中,有三个重要的角色。领域专家必须是由来自各行业的有一定工作年限和专业资质的资深人士担任,他们负责设计所在领域的 AI 数据格式,根据 AI 训练的需求制定统一的标准,规范标注数据的提交,同时还肩负了数据质量验收、上传的重担;数据标注师则来自世界范围内的各行各业,他们将以自身的专业知识和经验来进行数据标注,同时根据领域专家对已提交数据的评级,按照评级获取酬劳;知识矿工则需要将领域专家上传的数据打包至分布式存储,以供 AI 训练企业/机构下载,当然只是矿工也有治理权力,可以参与到领域专家选拔投票中,以维护整个“AI 数据标注系统”的良性发展。
而且,为了增加标注师工作的趣味性,铭识协议 EpiK Protocol 将这部分工作在终端以游戏通关的形式呈现(App名称:知识大陆),降低了参与门槛,让人人都可以成为 AI 的老师,同时也提升了标注师们的体验。

经过测试,以“知识大陆”形式收集 AI 标注数据的效率为传统标注收集方式的 10 倍左右。
开发开源 Firefox 浏览器的非营利组织 Mozilla 开源语音收集计划 Common Voice,用 2 年的时间,搜集到了 3501 条中文语音标注数据,占用存储 2.37 G,每条数据的人工校验次数平均为 3 次,数据来源的低于、性别和年龄指标不完整,覆盖地区不明、覆盖城市数量不明。而经过“知识大陆”试运行 3 周的数据来看,收集中文语音标注数据 17,272 条,且每条数据标注者所在地域、性别和年龄皆可溯源,全部占用存储 2.62 G,平均每条数据的人工校验次数为 10 次,数据来源覆盖国内 34 个省份,173 个城市。

与“AI 数据标注系统”相对应的,是铭识协议 EpiK Protocol 规划的“AI 数据存储系统”。
为了充分调动其每台闲置中的存储设备,在“AI 数据存储系统”中存储数据是免费的,且不限时间,默认无限存储份数,无需指定特定节点。平均每个扇区大小仅需 8M,相比于 FileCoin 32G的平均扇区大小,“AI 数据存储系统”的更节省空间,对存储设备的要求门槛更低,参与更容易。
不过,为了保证标注数据的存储质量,只有上传经过领域专家验证过的数据,才会计入算力。再一次通过规则来规避“脏数据”混入高质量的数据中。
去中心化存储能力加之 AI 数据处理协作网络,更加符合未来人工 AI 智能应用的使用和发展趋势,从而为互联网时代最主要的产物——数据,赋予更大的价值。
将分布式存储与 AI 智能相结合,构建去中心化的超大规模知识图谱,铭识协议 EpiK Protocol 的商业模式和理念已经得到了世界级人工智能专家——人工通用智能之父 Ben Goertzel 的认可,目前他是铭识协议的首席顾问。
Chainlink 等头部项目,清华大学等名校,都与铭识协议渊源匪浅。2021 年 1 月,铭识协议携手业内专家发起开源知识运动,在线研讨会议曾邀请清华大学信息技术研究院副院长邢春晓、中国计算机学会知识图谱 SIG 主席、著名知识图谱专家王昊奋、著名数据及知识图谱公司创始人及项目负责人王会珍等重量级嘉宾参与,该活动在人工智能及大数据领域引起广泛关注。
全球最大的 NGO 开源开放数据组织 Open Knowledge,全球最大的中文知识图谱库 OpenKG.CN,全球最大去中心化的数据交换协议 Ocean Protocol,全球最大的开放中文语音数据社区 OpenSLR,全球首个去中心化 AI 服务网络、全球首个机器人公民 Sofina 缔造者 SingularityNET,全球高质量 AI 数据提供者 iMerit 以及清华大学,都是铭识协议 EpiK Protocol 的公开合作伙伴。
此外,铭识协议还获得了 FBG、JACKDAW、CHAINUP CAPITAL 和共识实验室等知名投研机构的战略投资,累积金额超 800 万美元。
—
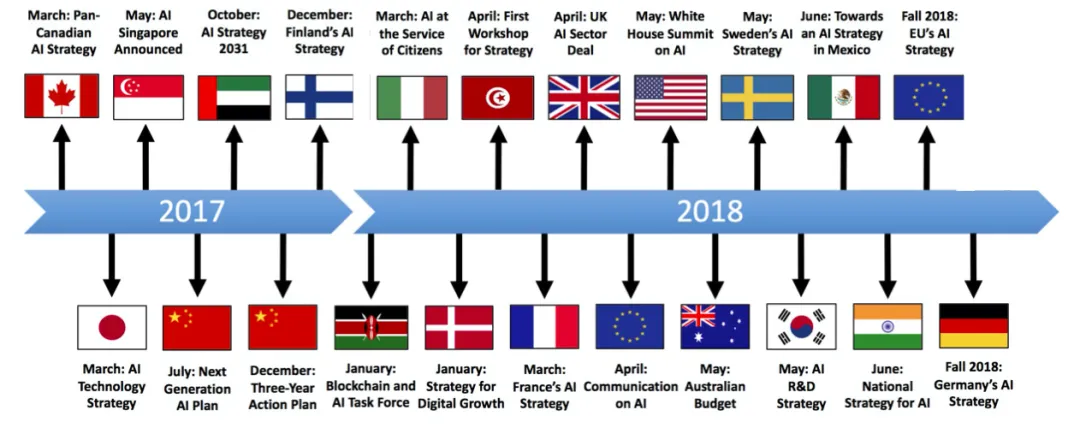
人工智能掀起了新的浪潮,各个国家纷纷制定了人工智能的发展战略。
美国在 2016 年先后发布了《为人工智能的未来做好准备》和《国家人工智能研究与发展战略规划》两份报告,将人工智能提升到了国家战略的层面。2018 年,白宫举办人工智能峰会,邀请业界、学术界和政府代表参与,并成立了人工智能特别委员会。日本、德国等多个国家也发布了相关的战略、计划,大力推进人工智能的发展。
2016 年,我国发布的《“十三五”国家科技创新规划》中,明确将人工智能作为发展新一代信息技术的主要方向。2017 年 7 月,国务院颁布《新一代人工智能发展规划》。2017 年 10 月,人工智能被写入“十九大报告”。2020 年,人工智能又作为“新基建”七大领域之一被明确列为重点发展领域。
在这个时代背景下,我们需要考虑人工智能未来十年会怎样发展。
统计数据告诉我们,任何事物都最可能处在它寿命的中间阶段,人类也不例外。人类科技文明的发展已经隐隐昭示我们正在进入一个艰难的瓶颈,人工智能 AI 会否是一条成功的出路?作为全球首个 AI 数据的分布式存储协议,铭识协议要做的,是为 AI 叩响智慧的大门,“这将是一场至少延续 50 年的碳基生命向硅基生命的史诗级布道”。